How Computers Learn from Data: A Beginner’s Guide

Table of Contents
“Understanding how computers learn from data is essential for anyone exploring AI and Machine Learning. This article breaks down machine learning in simple terms showing how models observe examples, make predictions, receive feedback, and improve over time making complex systems like recommendation engines, image recognition, and fraud detection understandable for beginners.”
Introduction
Have you ever wondered how Netflix seems to know what you want to watch next, how your phone instantly recognizes faces, or how banks detect fraud in seconds? The answer lies in machine learning (ML) — the science of teaching computers to learn from data.
Simply put, computers learn from examples, just like humans do. They observe patterns, make predictions, get feedback, and gradually improve. In 2026, this process powers nearly every intelligent system we use.
Let’s break it down step by step — no complex math, just the core concepts.
Step 1: Provide Examples (Training Data)
Computers start by learning from training data — a collection of examples where the correct answer is already known.
Examples:
- Images of cats and dogs labeled “cat” or “dog”
- Emails marked “spam” or “not spam”
- Loan applications labeled “approved” or “denied”
- Past customer purchases labeled “will buy again” or “will not buy”
High-quality, well-labeled data is crucial. The more examples the computer sees, the better it can learn patterns.
Step 2: Make a Guess (The Model Predicts)
The computer uses a model, which is like a flexible recipe with millions (or billions) of adjustable ingredients called parameters.
It examines an example (e.g., a picture of a cat) and predicts:
“I think this is 82% cat, 18% dog.”
Early guesses are usually wrong — just like a child learning to recognize animals.
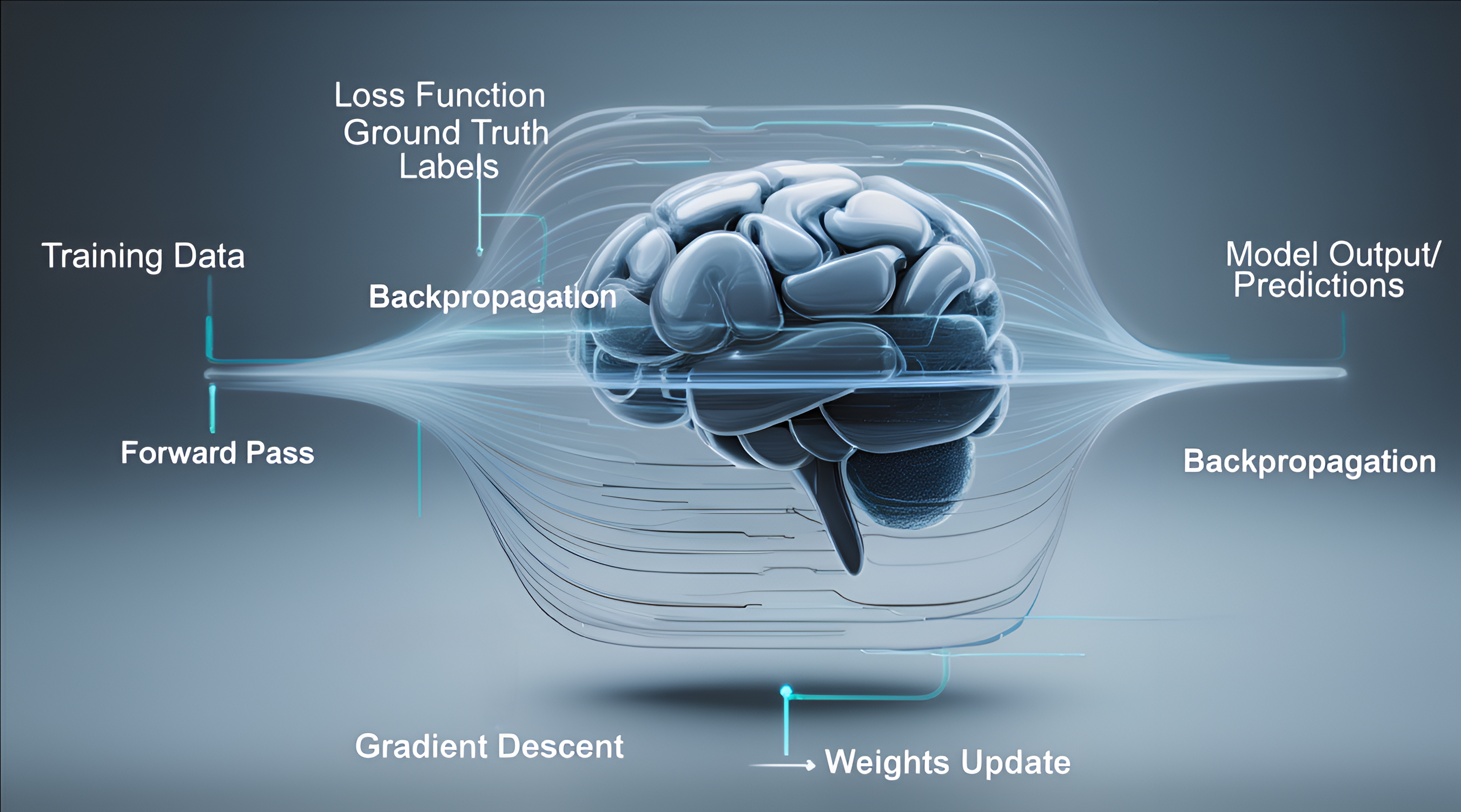
Step 3: Check How Wrong It Was (Loss / Error)
We measure the accuracy of the guess using a loss function — a score indicating how far the prediction is from the correct answer.
- If the model guessed 82% cat and the image is a cat → small error
- If it guessed 5% cat → large error
The goal: minimize errors across all examples.
Step 4: Adjust the Model (Learning with Backpropagation)
Next, the computer tweaks the model’s parameters to improve predictions.
- It calculates which parameters contributed to the error
- Figures out how much to adjust each one
- Makes tiny changes, repeated millions of times
This adjustment process is called gradient descent (improving the recipe step by step) and backpropagation (figuring out exactly where to adjust).
Step 5: Repeat Until Accurate (Epochs)
The computer goes through millions of examples repeatedly (called epochs).
- After a few passes → guesses go from random to okay
- After hundreds/thousands → predictions become highly accurate
The model is then tested on new, unseen data (validation/test set) to ensure it generalizes well. Once it performs consistently, it’s ready for real-world predictions — this is called inference.
Step 6: Think of It Like Teaching a Child
- Show labeled images (“cat,” “dog,” “bird”)
- Child guesses
- You correct mistakes
- Child adjusts mental rules (“fluffy + pointy ears = likely cat”)
- Repeat thousands of times → child becomes accurate
Machine learning does the same — millions of times faster, with mathematical precision.
Why Machine Learning Works So Well Today
- Massive datasets: Billions of examples online
- Powerful computers: GPUs and TPUs handling trillions of calculations per second
- Advanced algorithms: Transformers, diffusion models, and reinforcement learning
- Smart training methods: Pre-training, fine-tuning, and self-supervised learning
Modern models can learn language, vision, audio, and even robotics tasks that would take humans years to master.
Quick Summary: The Learning Loop
- Feed examples with correct answers → training data
- Model makes a guess → prediction
- Measure error → loss
- Adjust parameters → backpropagation & gradient descent
- Repeat many times → learning
- Test on new data → deploy for inference
That’s the essence of how computers learn from data.
Getting Started Yourself
You don’t need a supercomputer. Start small:
- Google Colab: Free GPU experiments
- Scikit-learn: Classic ML models for beginners
- Hugging Face: Pre-trained models for NLP, vision, and multimodal tasks
- Free Courses: Fast.ai, Kaggle Learn, Hugging Face courses
Even a simple spam detector, house-price predictor, or image classifier demonstrates the magic of ML.
Further Reading
- 3Blue1Brown – Neural Networks series (visual and intuitive)
- Fast.ai – Practical Deep Learning for Coders (free, beginner-friendly)
- “Deep Learning” by Goodfellow, Bengio, Courville (free online)
- Kaggle Learn – Free interactive ML courses
Recommended Insights
Continue your journey