What Training a Model Actually Means
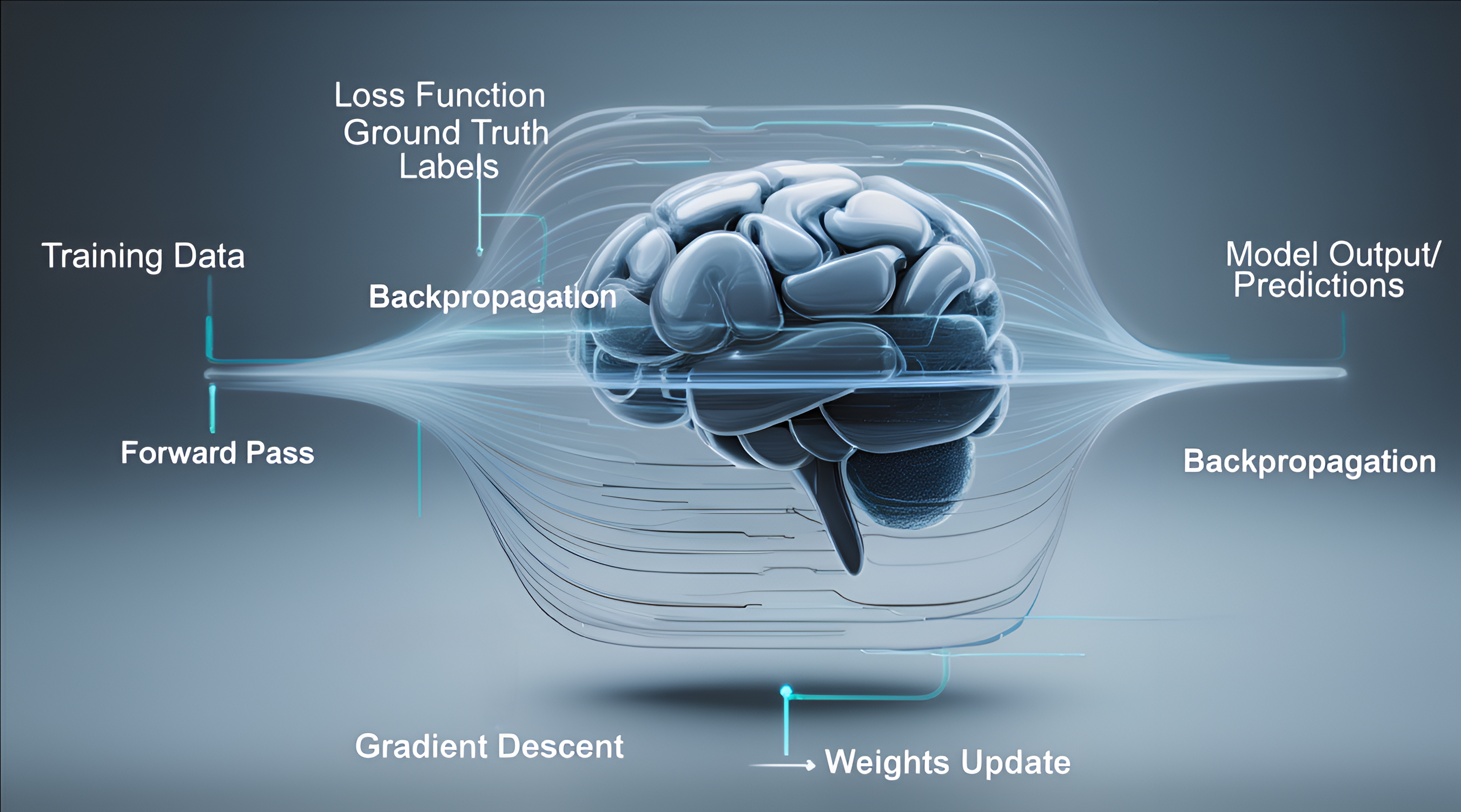
Table of Contents
“When people say “we trained an AI model,” it sounds mysterious, like some secret lab process. But the reality is surprisingly straightforward. Training a model is just teaching a computer to make better guesses by repeatedly showing it examples, checking how wrong it was, and making tiny corrections until the guesses become very accurate. This post explains exactly what happens during training step by step, no math overload, so you can understand why it takes so much time, data, and computing, and why it works so well in 2026”
What Is a “Model” in Machine Learning?
Before we talk about training, let’s define the star of the show: a model.
A model is simply a mathematical function (or recipe) with a bunch of adjustable numbers inside it called parameters or weights.
- These numbers start randomly.
- During training, the computer tweaks them repeatedly based on examples.
- After training, the tuned numbers become the “knowledge” the model uses to make predictions or generate new content.
Think of the model as a massive, adjustable calculator:
- Input goes in (a photo, a sentence, numbers)
- The model applies millions/billions of multiplications and additions using its learned weights
- Output comes out (a label, a probability, generated text, an image)
Training is the process of finding the perfect values for those weights so the calculator gives correct/useful answers most of the time.
Everything else — neural networks, layers, backpropagation is just a smart way to organize and adjust those numbers efficiently.
The Core Idea: Learning = Repeated Guess → Check → Adjust
Training is a feedback loop that runs millions or billions of times:
-
Show the model an example
Input: a photo of a cat
(or a sentence, a stock price history, a customer transaction, etc.) -
Model makes a guess (prediction)
Output: “92% chance this is a cat” -
Check how wrong it was
Compare the prediction to the true answer (the label)
Calculate loss/error — a single number saying “how bad was that guess?”
(High loss = very wrong; low loss = almost perfect) -
Adjust the model slightly
Use math (backpropagation + gradient descent) to figure out:- Which internal numbers (weights) contributed to the mistake
- In which direction and by how much to tweak them
Change each weight by a tiny amount (e.g., 0.0001), so the next guess on a similar example will be a little better
-
Repeat a lot
Do this for every example in your dataset
One full pass through all data = 1 epoch
Most models train for 10–100+ epochs → billions of individual adjustments
After enough repetitions, the model’s guesses become extremely accurate even on new data it has never seen before.
Why It’s Called “Training”
Think of it like training a child (or a dog):
- Show examples (“this is a cat”, “this is not a cat”)
- Child guesses
- You correct (“no, that’s a cat”)
- Child adjusts their mental rules slightly
- Repeat thousands of times → child becomes very good at recognizing cats
Training a model is the same, just millions of times faster and with mathematical precision instead of words.
What Actually Changes During Training?
Inside the model are billions of numbers called parameters (weights and biases).
- Before training: random values → guesses are basically random
- During training: each adjustment nudges these numbers slightly
- After training: tuned values → guesses are highly accurate
That’s it. Training = finding the perfect set of numbers that minimizes errors across your data.
Key Ingredients for Successful Training in 2026
-
Lots of good data
The more high-quality, diverse examples, the better the model learns real patterns (not noise). -
A suitable architecture
Transformers, diffusion models, CNNs, etc, each is good for different data types (text, images, etc.). -
Enough compute power
GPUs/TPUs — training large models can take weeks or months, even on thousands of chips. -
Smart optimization tricks
- Learning rate schedules
- Gradient clipping
- Mixed precision
- Mixture-of-Experts (only parts of the model activate)
-
Validation & testing
Always check performance on held-out data to avoid overfitting (memorizing training examples instead of learning general rules).
Quick Analogy: Training vs. Using the Model
- Training = teaching a student by giving practice questions, grading them, and correcting mistakes for months
- Inference (using the model) = giving the trained student a final exam — they answer quickly and accurately without further changes
Training is slow and expensive.
Inference is fast and cheap, that’s why you can use ChatGPT or Midjourney instantly.
Conclusion
Training a model means repeatedly showing it examples, measuring how wrong its predictions are, and making tiny adjustments to its internal numbers until those predictions become very accurate.
It’s a massive, automated trial-and-error process powered by data, compute, and clever math, not magic, but incredibly effective when scaled up.
By 2026, this same basic loop, guess, check, and adjust, has produced everything from fluent chatbots to photorealistic image generators and autonomous agents.
Understanding training helps you appreciate why data quality, compute power, and smart engineering matter so much and why the best models today are the ones that have been trained the longest and smartest.
Want to see it in action? Try Google Colab with a small scikit-learn or Hugging Face model you can train your first model in under 10 minutes.
References
- 3Blue1Brown — Neural Networks series (best visual intro)
- Fast.ai — Practical Deep Learning for Coders (free)
- “Deep Learning with Python” by François Chollet
- Kaggle Learn — Free interactive courses
- Hugging Face — Transformers & Diffusion documentation.
Recommended Insights
Continue your journey