Transformers - The Architecture Behind Modern AI
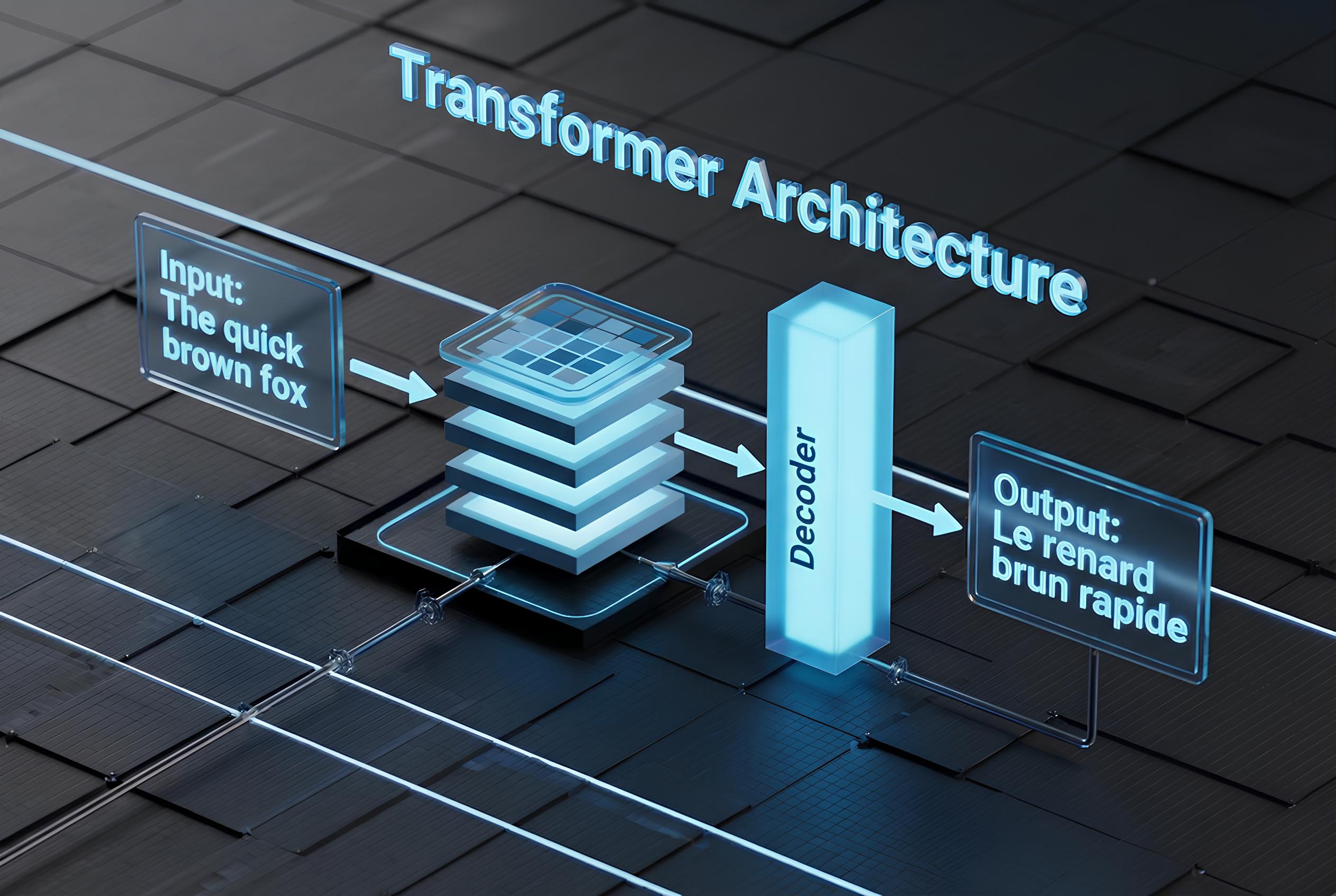
Table of Contents
“If you’re using ChatGPT, Claude, Gemini, Grok, Midjourney, or any of the powerful AI tools in 2026, you’re interacting with systems built on one core invention called Transformer.”
Introduction
The Transformer architecture. Introduced in the 2017 paper “Attention Is All You Need” by Vaswani et al., transformers completely changed how machines process sequences — text, images, audio, video, even robotics data — and became the foundation of almost every major AI breakthrough since 2018.
This post explains in clear, practical language what transformers are, how they work, why they replaced older models, and why they remain the dominant force in AI today.
What Problem Did Transformers Solve?
Before 2017, sequence models (RNNs, LSTMs, GRUs) were the standard for language, speech, and time-series tasks. They had a major weakness: They processed data one step at a time (sequentially), which made training slow and long-range dependencies hard to learn. A sentence like “The cat that was sitting on the mat yesterday is now sleeping” is difficult for RNNs because the connection between “cat” and “sleeping” is separated by many words — the memory fades (vanishing gradient problem).
Transformers fixed this with one radical idea: Instead of reading one word at a time, let every word look at every other word simultaneously. This is called self-attention, and it’s the heart of the transformer.
How Transformers Actually Work
A transformer is made of two main parts: encoder and decoder (though many modern models use only one).
1. Self-Attention (The Breakthrough)
Self-attention lets each word in a sentence “attend” to every other word — figuring out which words are most relevant to it. Example: In “The animal didn’t cross the street because it was too tired.”
- “it” should attend strongly to “animal” (not “street”)
How it’s calculated (simplified):
- Each word gets three vectors: Query, Key, Value (created by multiplying the word’s embedding by learned matrices)
- Compute similarity (dot product) between the query of one word and the ke of every word
- Softmax those similarities → attention weights
- Weighted sum of Values → new representation of the word, now enriched with context from the whole sentence
This happens in parallel for every word — no sequential bottleneck.
2. Multi-Head Attention
Instead of one attention pass, transformers do many in parallel (“heads”), each focusing on different relationships (syntax, semantics, coreference, etc.).
8–64 heads are common → richer understanding.
3. Positional Encoding
Since attention doesn’t care about order, transformers add special positional encodings to word embeddings so the model knows “first word”, “second word”, etc.
4. Feed-Forward Layers & Residual Connections
After attention, each position goes through a small feed-forward network.
Residual connections + layer normalization keep gradients flowing smoothly through many layers.
5. Encoder vs Decoder
- Encoder — reads the full input sequence (e.g., source sentence for translation)
- Decoder — generates output one token at a time, attending to both its own previous outputs and the encoder’s representation
Most 2026 LLMs (GPT, Claude, Grok, Llama) are decoder-only transformers — they generate autoregressively without a separate encoder.
Why Transformers Took Over
| Property | RNNs / LSTMs (pre-2017) | Transformers (2017+) |
|---|---|---|
| Training speed | Sequential (slow) | Parallelizable (very fast on GPUs) |
| Long-range dependencies | Hard (vanishing gradients) | Easy (direct connections) |
| Scalability | Poor (can’t use huge batches) | Excellent (scales to trillions of params) |
| Multimodal capability | Difficult | Natural (ViT, Flamingo, LLaVA, etc.) |
| State in 2026 | Mostly legacy | Dominant (LLMs, vision, audio, robotics) |
Transformers enabled:
- Models with 100B–2T+ parameters
- Training on internet-scale text
- Emergent abilities (reasoning, in-context learning, few-shot performance)
Modern Variants in 2026
- Decoder-only — GPT, Llama, Grok, Claude (pure generation)
- Encoder-only — BERT-style (understanding tasks)
- Encoder-decoder — T5, BART, Flan-T5 (translation, summarization)
- Vision Transformers (ViT) — images as sequences of patches
- Multimodal — Flamingo, LLaVA, Chameleon (text + image + video)
Conclusion
The transformer architecture replaced sequential processing with parallel self-attention, allowing models to look at entire contexts at once. This single change unlocked massive scale, long-range understanding, and multimodal capabilities — making it the foundation of modern AI.
In 2026, almost every frontier model you interact with is either a transformer or heavily influenced by transformer design. Understanding attention is understanding why today’s AI feels so intelligent, flexible, and powerful.
Want to go deeper? Try the Hugging Face Transformers library — you can run a small transformer in Google Colab in under 10 minutes.
References
- Vaswani et al. — “Attention Is All You Need” (2017)
- Hugging Face Transformers Course (free)
- “The Illustrated Transformer” by Jay Alammar (visual guide)
- Stanford CS224n — Natural Language Processing with Deep Learning
- Lilian Weng — “The Transformer Family” blog series.
Recommended Insights
Continue your journey