How Generative AI Actually Generates Images and Text

Table of Contents
“Generative AI creates images and text by learning statistical patterns from large datasets and generating new content through probabilistic sampling. Text is produced by transformer models predicting the next token step by step, while images are generated by diffusion models that refine random noise into realistic visuals. Rather than copying data, generative AI recombines learned patterns to create novel outputs. For deeper insight, see the sections below on training, diffusion models, and autoregressive transformers.”
Introduction
Generative AI feels like magic: type a sentence and get a stunning image, or give a prompt and receive polished, human-like text in seconds.
But behind the scenes, it’s not magic; it’s clever mathematics, massive data, and a few key tricks that have evolved dramatically by 2026.
This post explains in plain language how modern generative AI creates images (like Midjourney, DALL·E 3, Stable Diffusion 3) and text (like ChatGPT, Claude, Gemini, Grok).
No heavy equations, just the real process step by step.
Two Main Families in 2026
Most generative models today belong to one of two powerful approaches:
- Diffusion models → dominate image generation (Stable Diffusion, Midjourney, Flux, Imagen 3)
- Autoregressive / transformer-based models → dominate text generation (GPT-4o, Claude 3.5, Gemini 2, Grok-2, Llama 3.1)
They look different, but both follow the same core philosophy:
Learn the probability distribution of real data → then sample from it to create new, realistic examples.
Let’s see how each family actually works.
How Diffusion Models Create Images
Diffusion models (the engine behind almost all high-quality AI art in 2026) are based on a surprisingly elegant idea:
Start with pure random noise → slowly remove the noise until a realistic image appears.
The Training Phase (Learning to “Un-noise”)
- Take a real photo (e.g., a cat on a sofa).
- Gradually add random noise over many steps — after ~100–1000 steps the image becomes pure static (Gaussian noise).
- Train a neural network (usually a U-Net) to reverse the process:
- Show it a noisy version
- Ask it to predict what the noise was that was added
- Subtract that predicted noise → get a slightly cleaner image
- Repeat this millions of times across billions of images → the network learns how noise is typically added to real-world pictures.
The Generation Phase (Creating New Images from a Prompt)
- Start with pure random noise (static TV screen).
- Give the model a text prompt (“a cat wearing sunglasses on a beach at sunset”).
- Use a text encoder (CLIP or T5) to turn the prompt into a numerical “guidance signal”.
- For 20–50 steps:
- Feed the current noisy image + prompt guidance to the model
- Model predicts what noise is present
- Subtract that noise → image becomes slightly clearer
- After the final step → you get a sharp, realistic image that never existed before.
That’s it. The model never “draws” — it denoises random static into something meaningful, guided by your text.
Why it looks so good in 2026:
- Bigger models (1–12 billion parameters)
- Better text encoders
- Fine-tuning on high-quality aesthetic datasets
- Advanced sampling tricks (DPM++ 2M Karras, ancestral sampling)
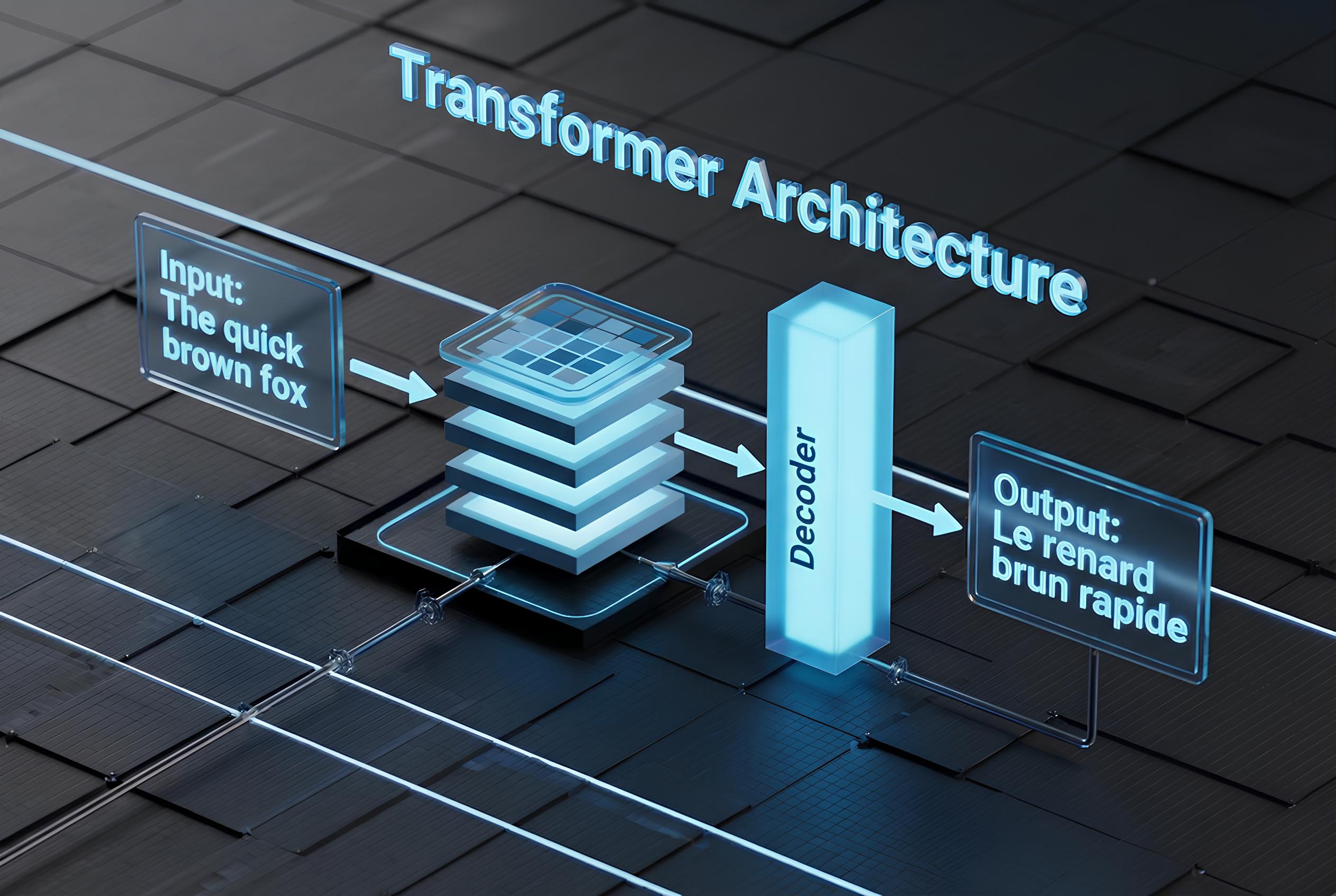
How Autoregressive / Transformer Models Create Text
Text generation in 2026 (ChatGPT, Claude, Gemini, Grok, Llama, etc.) uses next-token prediction — the same idea scaled to trillions of tokens.
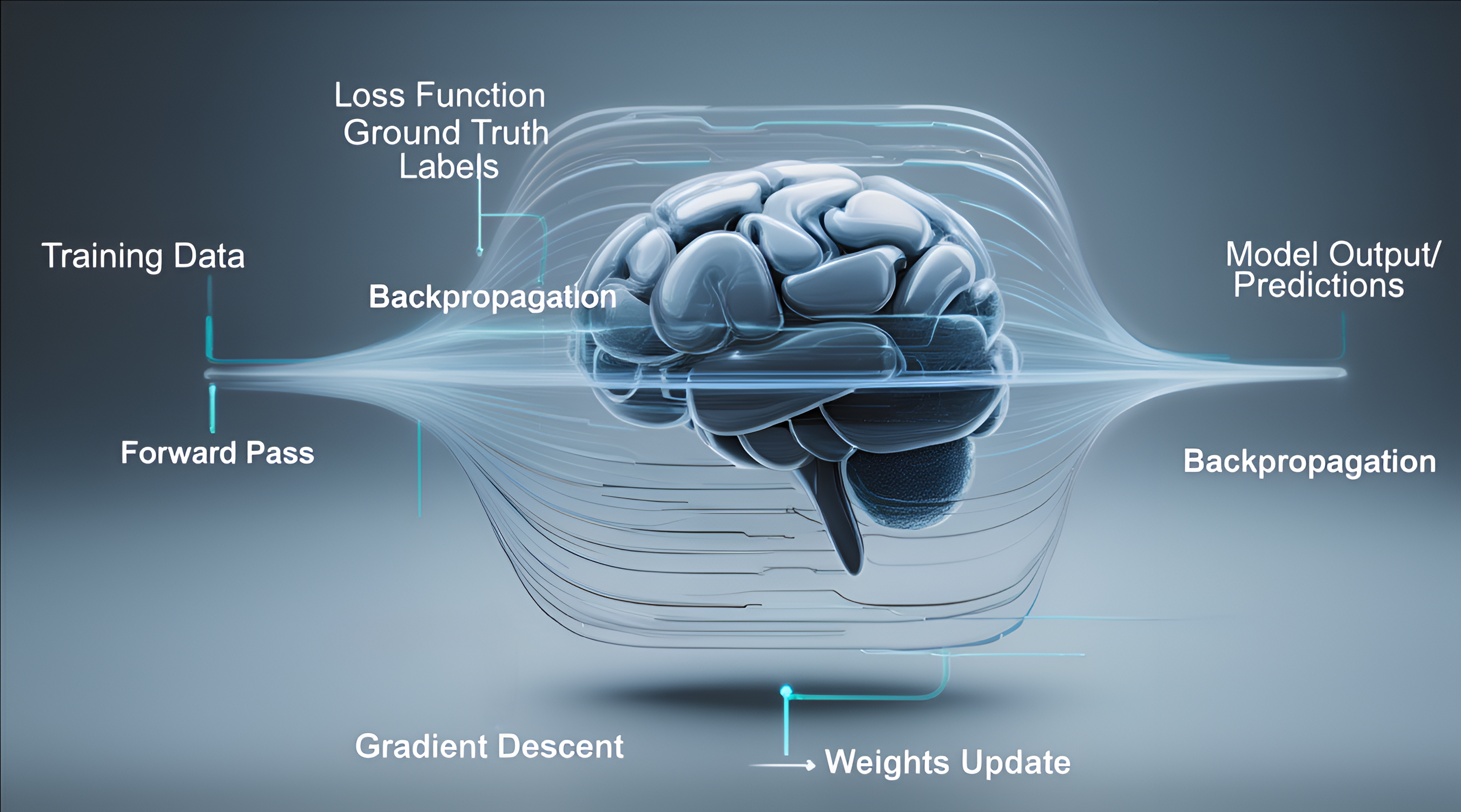
The Training Phase (Learning What Comes Next)
- Feed the model enormous amounts of text (books, websites, code, forums — basically the entire internet + books).
- Hide the next word/token and ask the model to guess it.
- “The capital of France is” → predict “Paris.”
- “Hello, how are” → predict “you.”
- When wrong, adjust the model slightly (backpropagation + gradient descent).
- Repeat trillions of times → the model learns the statistical patterns of human language extremely well.
The Generation Phase (Producing Text)
- Give the model your prompt (“Write a blog post about…”).
- The model outputs probabilities for the next token (word piece).
- “The” → 12% chance next is “quick”, 8% “brown”, 0.001% “xylophone.”
- Sample one token (usually the most likely, or slightly random for creativity).
- Append it to the prompt → repeat.
- Keep going until it predicts an end-of-sequence token or reaches max length.
That’s why it can write essays, code, poems — it has internalized billions of patterns of what usually comes next in human text.
Modern improvements in 2026:
- Longer context windows (128k–1M tokens)
- Better reasoning via chain-of-thought training
- Mixture-of-Experts (only parts of the model activate)
- Post-training alignment (RLHF, DPO) to make responses helpful & safe
Side-by-Side Comparison
| Aspect | Diffusion (Images) | Autoregressive Transformers (Text) |
|---|---|---|
| Core idea | Start with noise → remove noise step by step | Predict next token → keep adding |
| Output process | Fixed number of denoising steps (20–50) | One token at a time (autoregressive) |
| Creativity source | Random noise + prompt guidance | Sampling from probability distribution |
| Training goal | Predict added noise | Predict next word/token |
| Dominant models (2026) | Stable Diffusion 3, Flux, Midjourney v6 | GPT-4o, Claude 3.5, Gemini 2, Grok-2 |
| Typical use | Art, photos, design, video frames | Chat, writing, code, reasoning |
Why This Feels Like Magic (But Isn’t)
Both approaches are just very good statistical pattern matchers trained on enormous data.
- They don’t “understand” like humans
- They don’t have imagination
- They excel at interpolation — remixing patterns they’ve seen billions of times
But because the training data is so vast and the models so large, the remixes often look creative, coherent, and novel.
Quick Recap: The Core Idea
Computers don’t create from nothing.
They learn the statistical “shape” of real data (images, text) → then sample new examples from that learned distribution.
- Images → denoise random static into realistic pictures
- Text → predict one word at a time until a complete response appears
That’s the whole trick — scaled to billions of parameters and trillions of training examples.
Conclusion
Generative AI doesn’t truly “create” as humans do. Instead, it learns the statistical patterns of real images and text from massive datasets, then cleverly samples and refines new examples that feel original and coherent.
Diffusion models turn noise into pictures through progressive denoising, while transformer models build text one token at a time through next-word prediction. Both rely on the same fundamental principle: mastering probability distributions of real-world data.
This technology has democratized creativity and productivity, making high-quality image and text generation accessible to anyone with a prompt. As models continue to improve in efficiency and quality, generative AI will become an even more powerful tool for artists, writers, developers, and everyday users.
Understanding these core mechanisms helps you craft better prompts, set realistic expectations, and appreciate the engineering behind the magic.
References & Further Reading
- Ho et al. — "Denoising Diffusion Probabilistic Models" (2020)
- Vaswani et al. — "Attention Is All You Need" (2017)
- Goodfellow et al. — Deep Learning (MIT Press)
- Hugging Face Diffusion Models Course (free)
- Stability AI Blog & Research Papers (Stable Diffusion)
- OpenAI Technical Reports (GPT series)
- Anthropic & Google DeepMind research updates (2025–2026)
Recommended Insights
Continue your journey