What actually is deep Learning ?

Table of Contents
“This article explains deep learning from first principles: what it is, how it works, how it differs from traditional machine learning, the major types of deep learning models (with more detailed breakdowns), and why it matters today — without relying on equations or unnecessary jargon.”
Introduction
Deep learning is one of the most widely used and most misunderstood terms in modern artificial intelligence. It appears everywhere: large language models, facial recognition, self-driving cars, medical imaging, and content generation systems.
But what exactly is deep learning, and why has it become so central to AI by 2026?
By the end, you’ll have a solid grasp of the concepts, real-world applications, and even limitations, so you can better understand (or even start experimenting with) this powerful technology.
What Is Deep Learning?
Deep learning is a subset of machine learning that uses neural networks with many layers to learn complex patterns directly from data automatically.
To break it down:
- Machine learning is the broad field where computers learn from data without explicit programming.
- Deep learning takes this further by stacking multiple layers of artificial neurons (inspired by the brain) to handle increasingly sophisticated tasks.
Unlike traditional machine learning, where humans often need to manually select or engineer features (e.g., "look for edges in an image to detect objects"), deep learning models discover those features themselves. They start with raw input (such as pixels in a photo or words in a sentence) and gradually build up understanding through layers.
For example:
- Input: A photo of a cat
- Traditional ML: You define features like "fur texture" or "ear shape."
- Deep learning: The model learns these automatically by seeing thousands of cat photos
This automatic feature learning is what makes deep learning so effective for complex, unstructured data like images, speech, text, and video.
The Core Learning Process
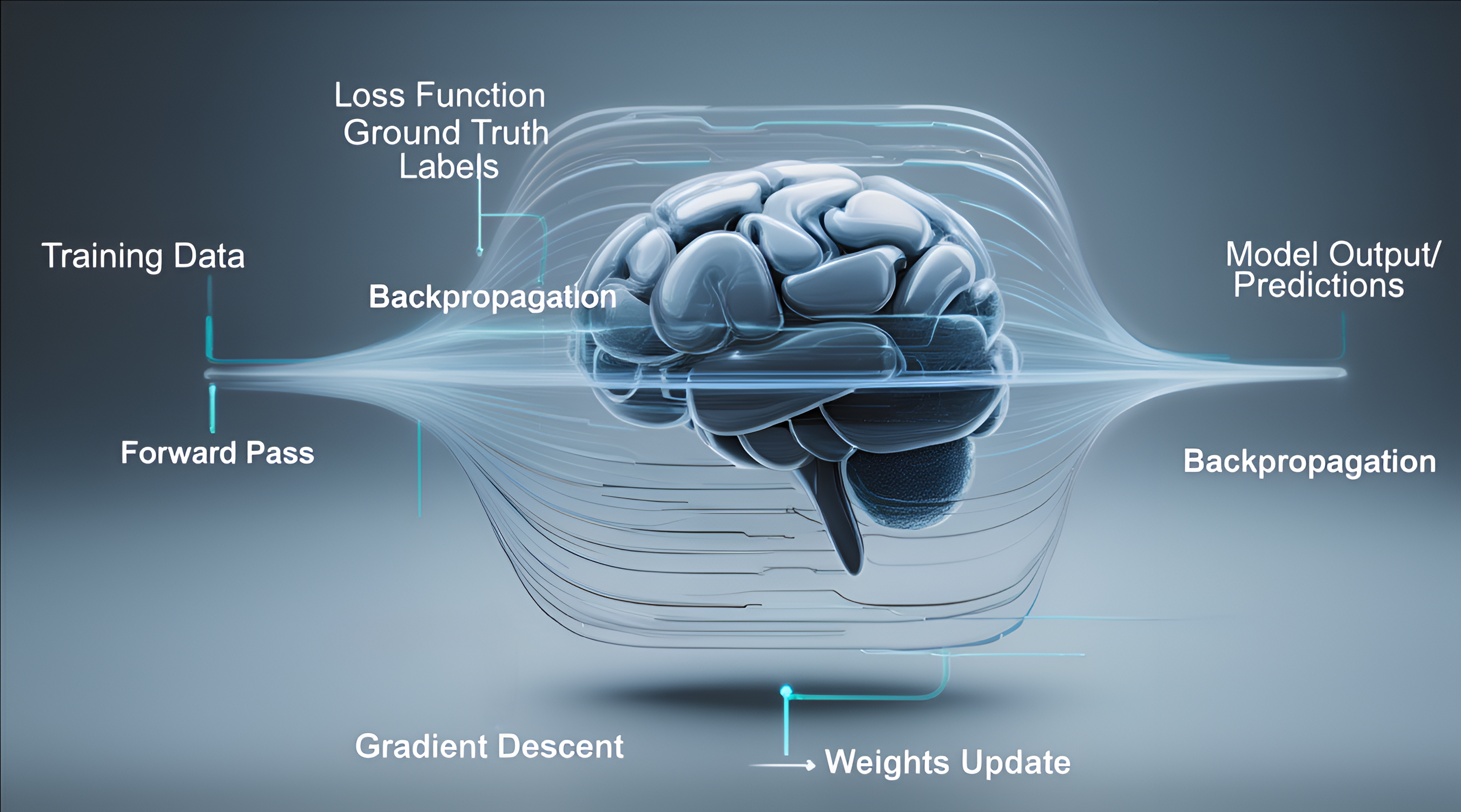
At its core, deep learning follows a simple feedback loop that is repeated at a massive scale. This process, called training, teaches the model to make accurate predictions or generate new content.
-
Input data is provided
The model receives large amounts of labeled examples (supervised learning) or unlabeled data (unsupervised/self-supervised).
Example: Millions of images labeled "cat," "dog," "car," etc. Or billions of sentences from books and websites. -
The neural network makes a prediction
Data flows through multiple layers of neurons. Each neuron performs a small calculation: multiply inputs by weights, add biases, and apply an activation function (like ReLU, which decides if the neuron "fires").
The output is a guess, such as "this image is 85% likely a cat." -
Error is measured
Compare the prediction to the true label using a loss function (e.g., cross-entropy for classification). This quantifies "how wrong" the guess was.
High loss = bad guess; low loss = good guess. -
The model adjusts itself
Using backpropagation (propagating the error backward through layers) and gradient descent (finding the direction to tweak weights that reduces loss the most), the model updates its millions/billions of parameters slightly.
Think of it as turning thousands of tiny knobs to make the next prediction a little better. -
The cycle repeats
This loop runs for thousands of iterations (called epochs) until the loss is minimized and the model performs well on new, unseen data (tested via validation sets to avoid overfitting).
Once trained, the model can infer on new data — making predictions or generating content quickly.
Why Depth Matters
The "deep" in deep learning refers to having many layers (often 10–100+ in 2026 models). Each layer builds on the previous one:
- Shallow layers learn basic features: edges, colors, simple shapes in images; individual words or sounds in text/audio.
- Deeper layers combine these into more abstract concepts: faces, objects, scenes in images; sentences, context, meaning in text.
This hierarchy allows deep learning to solve problems that shallow models can't — like translating languages with nuance or generating realistic photos from text descriptions.
However, more depth means more complexity: bigger models need more data, compute, and careful design to avoid issues like vanishing gradients (where learning signals fade).
Types of Deep Learning Models
Different problems require different architectures. Here are the major types in 2026, with more details on how they work and what they're best for.
1. Feedforward Neural Networks (FNNs)
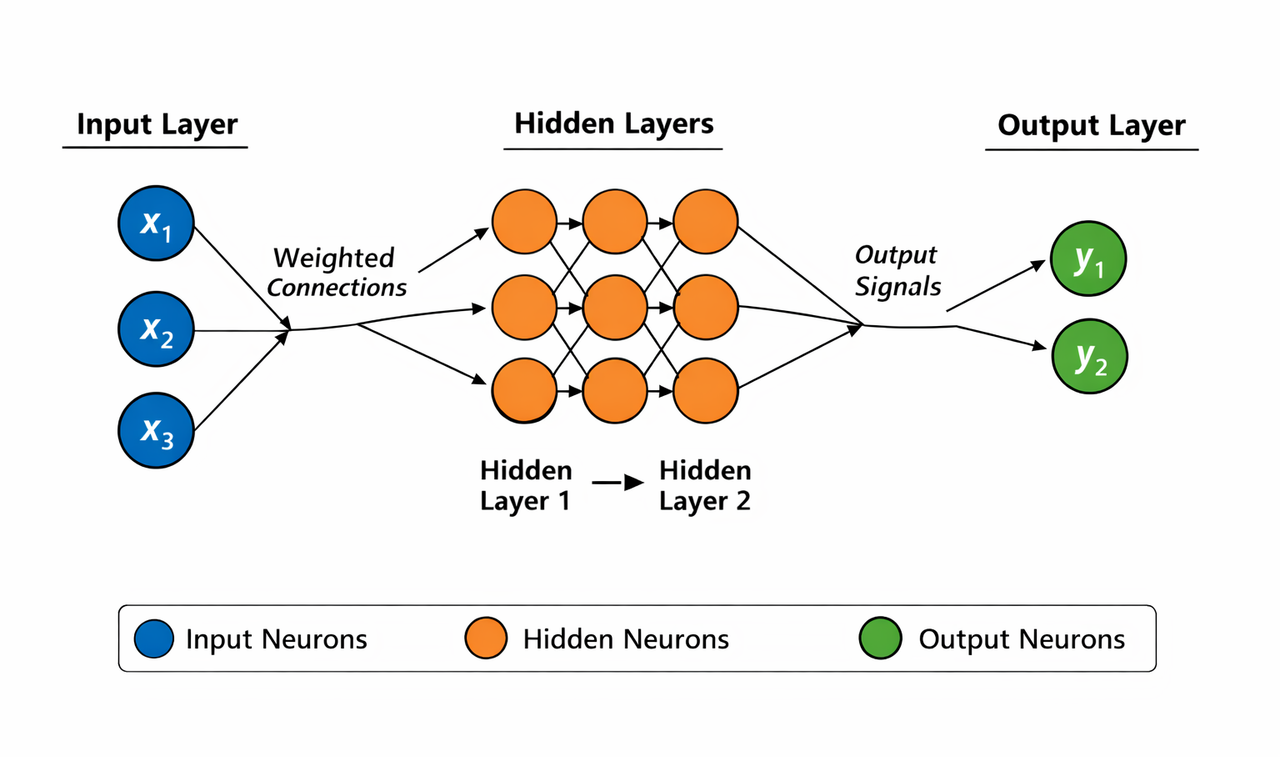
These are the simplest deep networks where data flows forward through layers without loops.
- How it works: Input → hidden layers (processing) → output. Each layer transforms data using weights/biases/activations.
- Best for: Basic classification/regression on structured data (e.g., predicting prices from features).
- Pros: Easy to understand and train.
- Cons: Not great for sequences or images (no spatial/sequential awareness).
- 2026 use: Baseline models or embedded in larger systems.
2. Convolutional Neural Networks (CNNs)
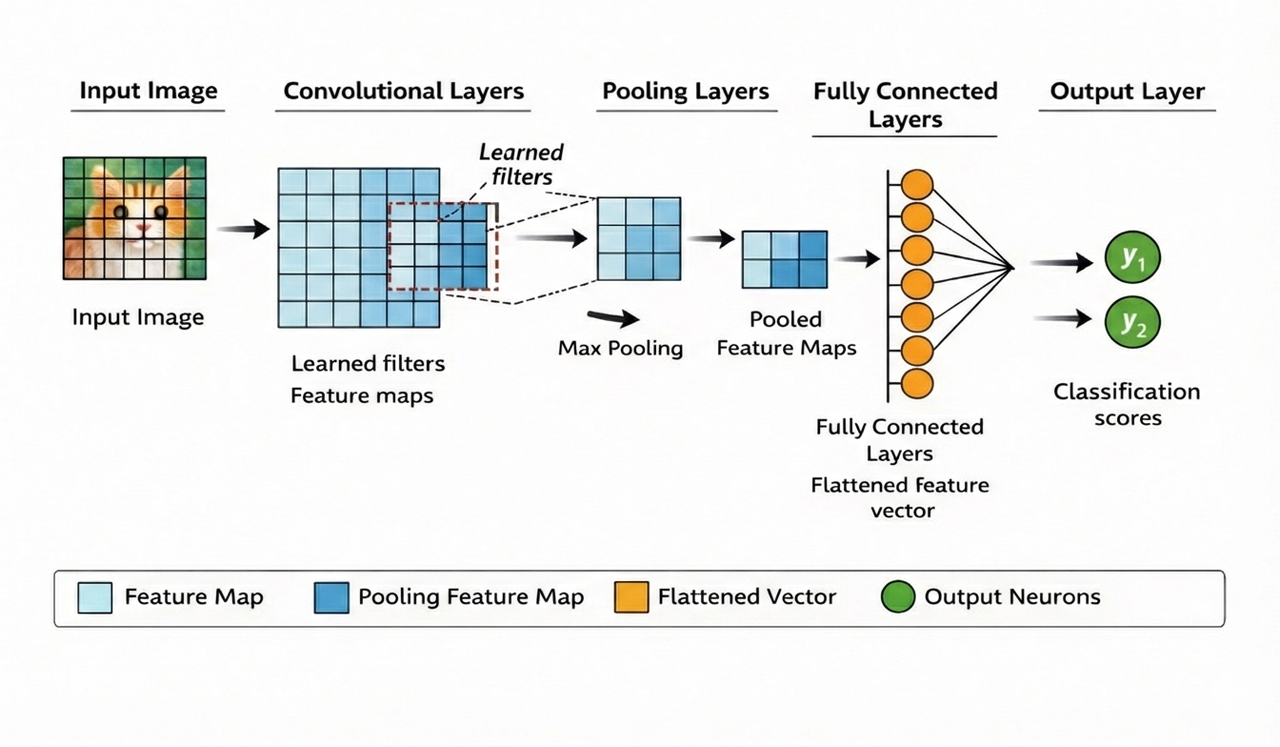
CNNs use convolution layers to scan data like a sliding window, detecting local patterns.
- How it works: Convolution filters extract features (edges, textures); pooling reduces size; fully-connected layers classify.
- Best for: Images/video (classification, detection, segmentation).
- Pros: Efficient on grid data, translation-invariant (recognizes objects anywhere).
- Cons: Less effective for non-spatial data.
- 2026 use: Facial recognition, medical scans, autonomous driving.
3. Recurrent Neural Networks (RNNs)
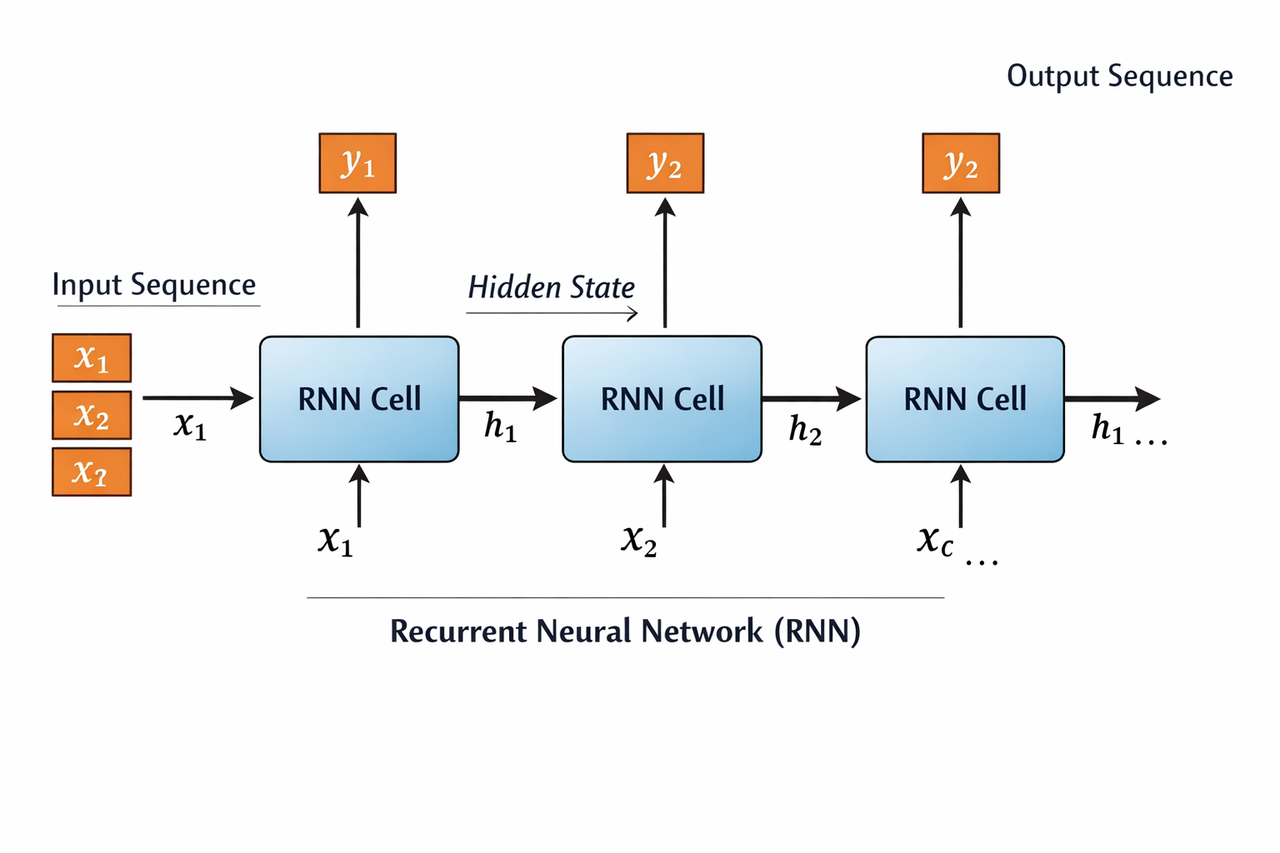
RNNs have loops to maintain memory of previous inputs, ideal for sequences.
- How it works: Hidden state carries information across time steps; processes sequences one element at a time.
- Best for: Time series, speech, early language tasks.
- Pros: Handles variable-length sequences.
- Cons: Prone to vanishing/exploding gradients; slower for long sequences.
- 2026 use: Stock prediction, music generation; largely replaced by transformers for text.
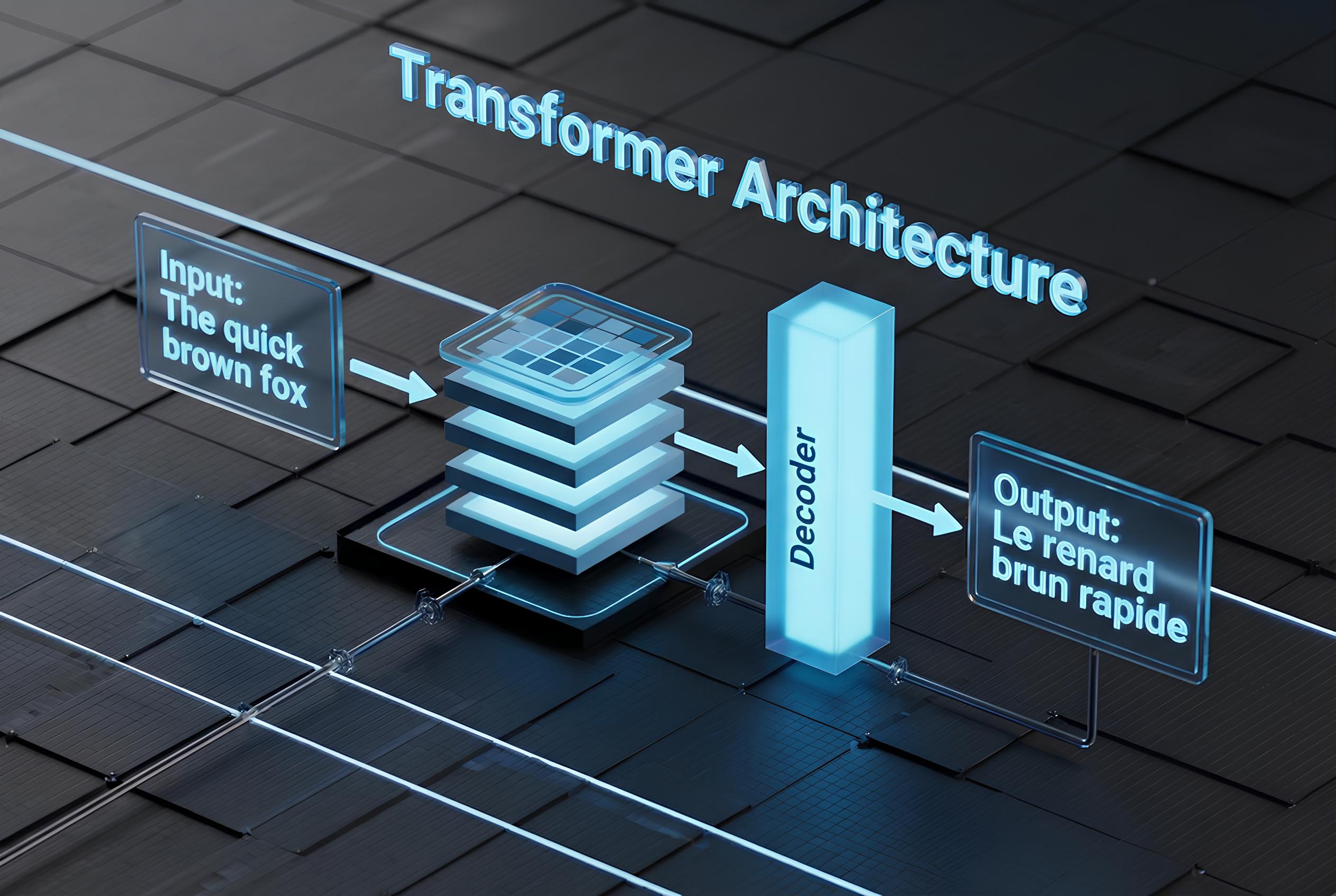
4. Transformer Models
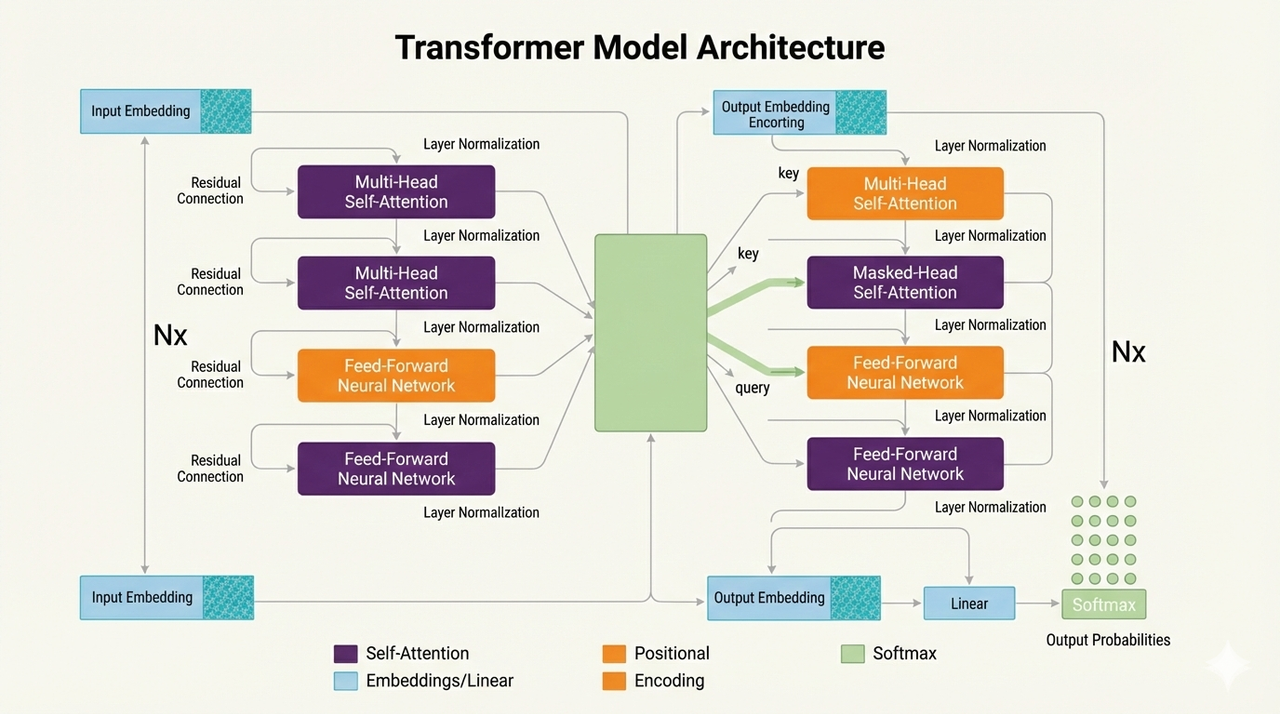
Transformers use self-attention to process entire sequences at once, without recurrence.
- How it works: Attention mechanism weighs input importance; encoders/decoders handle input/output.
- Best for: NLP, vision (ViTs), multimodal tasks.
- Pros: Parallelizable, handles long contexts well.
- Cons: Requires lots of data/compute.
- 2026 use: ChatGPT, translation, code generation, image synthesis.
5. Autoencoders
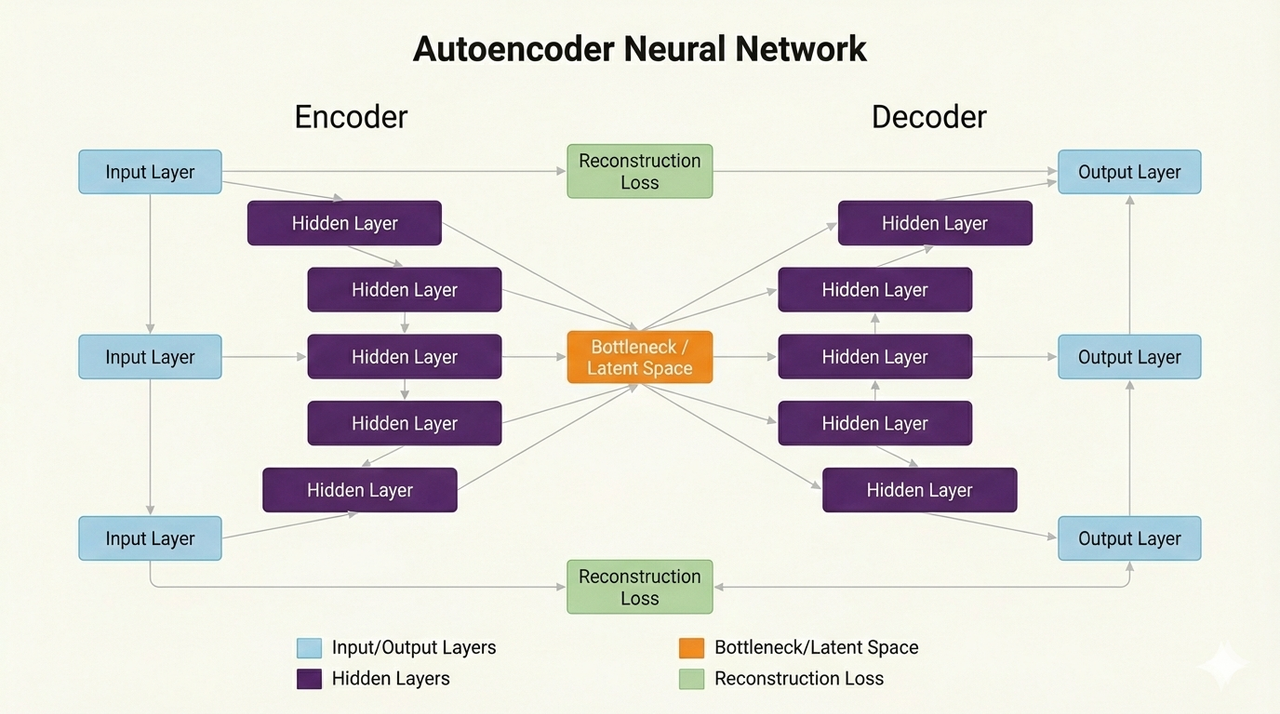
Autoencoders learn compressed representations by encoding/decoding data.
- How it works: Encoder compresses input; decoder reconstructs it; learns efficient representations.
- Best for: Denoising, dimensionality reduction, anomaly detection.
- Pros: Unsupervised (no labels needed).
- Cons: Less common for end-to-end tasks.
- 2026 use: Fraud detection, image compression.
6. Generative Models
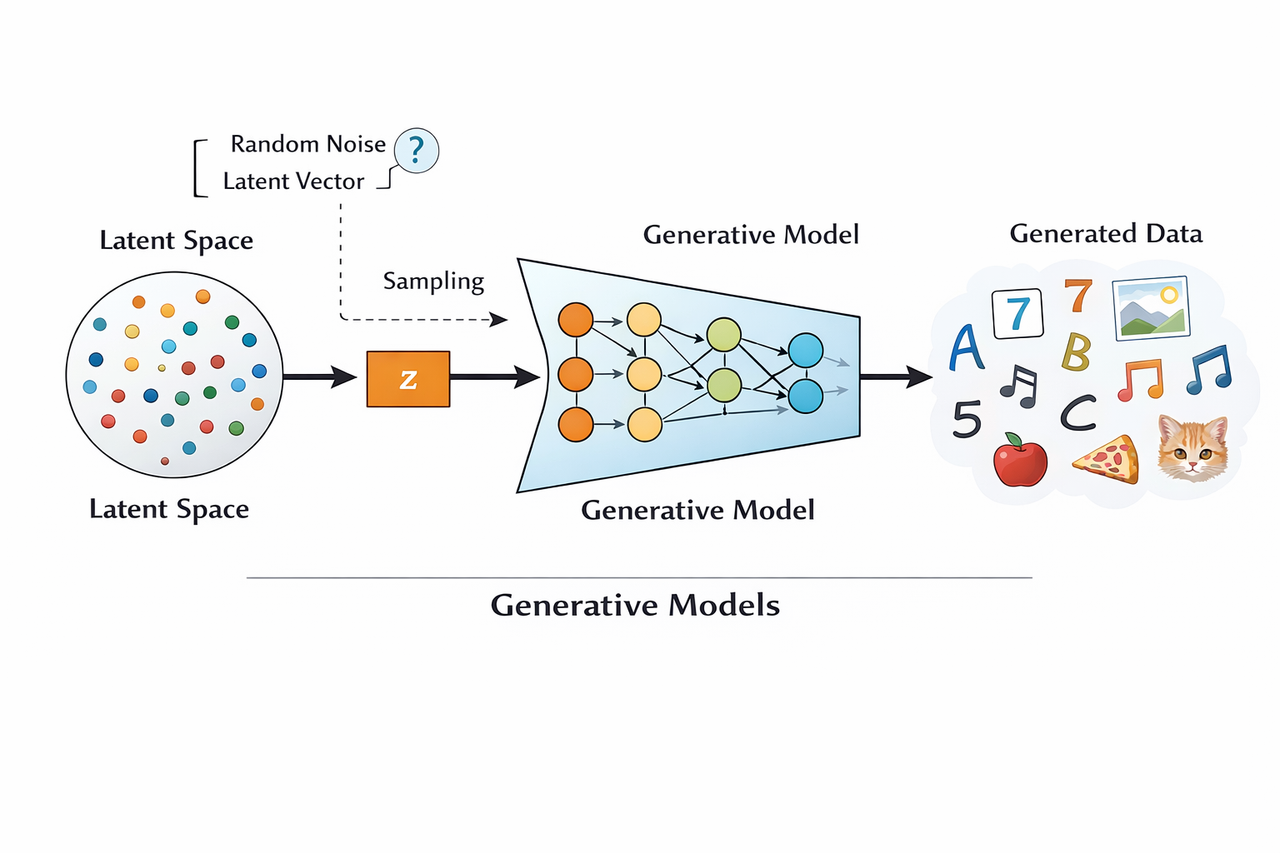
These generate new data samples from learned distributions.
- How it works: GANs (two networks compete); VAEs (probabilistic encoding); Diffusion (noise addition/removal).
- Best for: Image/video synthesis, data augmentation.
- Pros: Creates realistic new content.
- Cons: Can be unstable to train.
- 2026 use: DALL·E, Midjourney, Stable Diffusion for art; synthetic data for training.
Deep Learning vs Traditional Machine Learning
| Aspect | Traditional Machine Learning | Deep Learning |
|---|---|---|
| Feature engineering | Manual | Automatic |
| Data requirements | Small to medium datasets | Large datasets |
| Model size | Small | Large |
| Interpretability | High | Lower |
| Best suited for | Structured data | Unstructured data |
| Training time | Minutes to hours | Hours to weeks |
| Typical accuracy | Good, but plateaus | Extremely high on complex tasks |
Why Deep Learning Became Dominant
Deep learning’s success stems from:
- Massive data availability (internet-scale datasets)
- Powerful hardware (GPUs, TPUs, cloud compute)
- Breakthrough architectures (CNNs in 2012, transformers in 2017)
- Efficient training techniques (transfer learning, self-supervision)
By 2026, you can train effective deep models on a laptop — or use pre-trained ones from Hugging Face for free.
Limitations of Deep Learning
- Requires huge data and computing
- Often a "black box" (hard to explain why it made a decision)
- Can overfit or hallucinate
- Not true intelligence — just pattern matching
Conclusion
Deep learning is a powerful subset of machine learning that uses multi-layered neural networks to automatically learn complex patterns from raw data. Its hierarchical structure enables it to excel at perceptual and sequential tasks, making it the backbone of modern AI systems, from language models to image generation.
While it has limitations like high resource needs and interpretability challenges, its ability to handle unstructured data and scale with compute has made it indispensable in 2026. Understanding deep learning opens doors to building smarter systems and appreciating the technology shaping our world.
References
- Goodfellow, Bengio, Courville — Deep Learning (MIT Press)
- Vaswani et al. — Attention Is All You Need
- LeCun, Bengio, Hinton — Deep Learning (Nature)
- Stanford CS231n — Convolutional Neural Networks
- Fast.ai — Practical Deep Learning for Coders
- Hugging Face — Deep Learning and Transformer Documentation.
Recommended Insights
Continue your journey